
parallel PIC
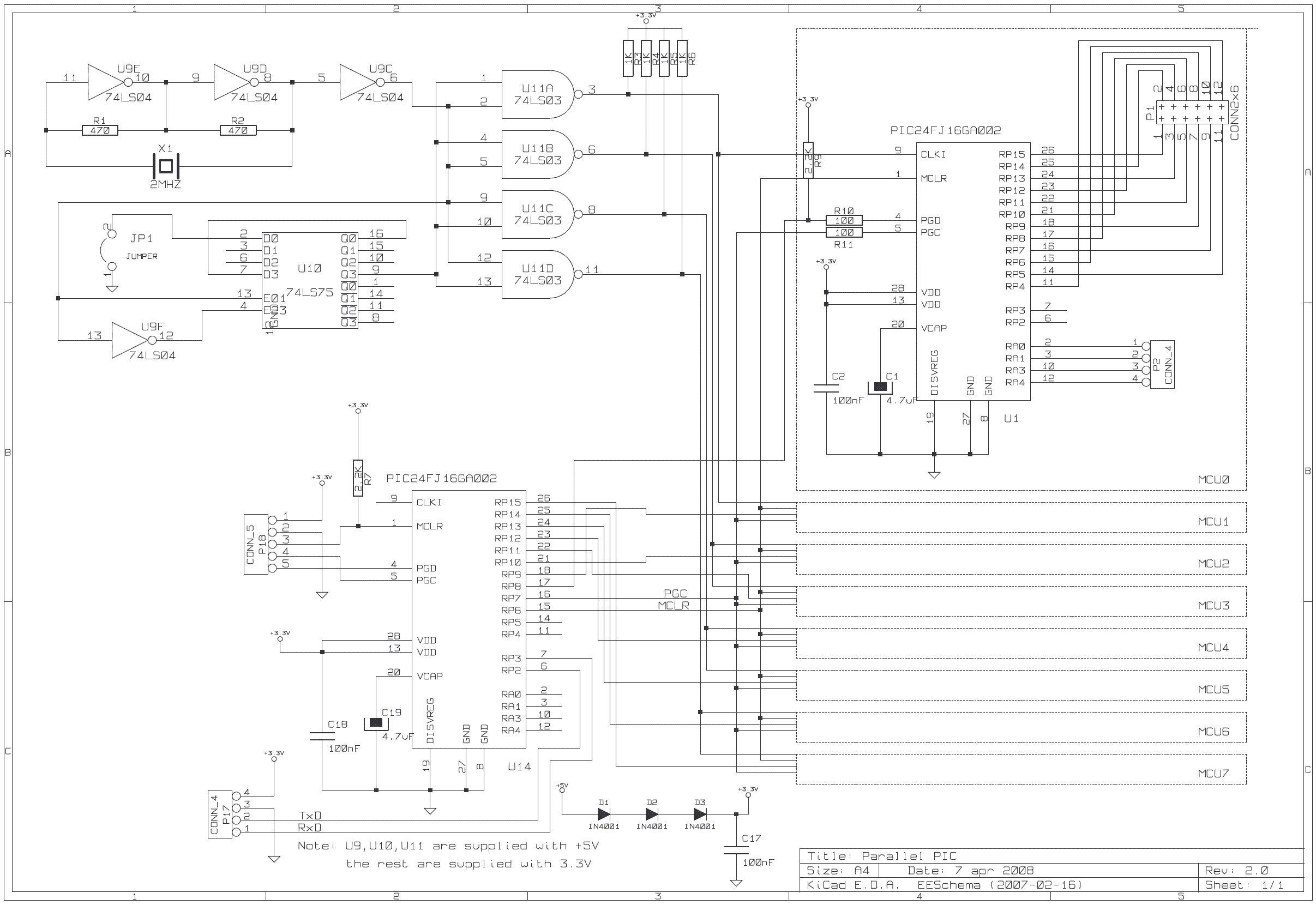
The described project focuses on a parallel processing computer that leverages multiple microcontrollers, enabling concurrent problem-solving capabilities. The architecture is based on the SIMD model, allowing all MCUs to execute the same instruction set while processing distinct data inputs. This design supports various applications, particularly in educational and performance-critical environments such as Digital Signal Processing.
The interconnection network among the MCUs is a pivotal component of this architecture. The choice of topology—whether it be a mesh, binary tree, or other configurations—directly affects the efficiency and speed of data exchange and algorithm execution. For example, in a binary tree topology, the hierarchical structure facilitates a systematic comparison of data values, enabling the determination of maximum values efficiently through a series of comparisons and data transfers.
The implementation of parallel algorithms is crucial for maximizing the performance of this system. Algorithms must be carefully designed to minimize communication overhead and optimize the workload distribution among the MCUs. The project documentation provides detailed insights into various algorithms suitable for this architecture, illustrating their practical applications and performance metrics.
Furthermore, the supporting software and firmware play essential roles in managing the interactions between the MCUs and coordinating the execution of parallel algorithms. The provided source code and firmware files serve as valuable resources for developers and researchers interested in exploring and expanding upon the capabilities of this parallel processing computer. Overall, this project exemplifies the potential of distributed computing through microcontroller networks, offering significant educational and practical opportunities in the field of parallel processing.The purpose of this project is to construct a computer that uses the combined computational power of many microcontrollers (MCUs). All the MCUs cooperate to solve one problem. The computer is defined as parallel processing machine and the algorithms that are executed on it are called parallel algorithms .
The machine can be used as an educat ional system that will help the development, understanding and fine-tuning of many parallel algorithms. It can also be used to achieve high performance in many cases such as in Digital Signal Processing. The computer can be easily constructed by an amateur. However the efficient use of it requires more effort as the development and implementation of parallel algorithms is a rather difficult task.
The next section makes a brief introduction to parallel processing computers. Section 3 describes the hardware, while section 4 describes the supporting software (i. e. the software that runs on the PC plus the firmware that lies on the "parallel computer" board). Section 5 explains and demonstrates some parallel algorithms that run on this parallel computer. Finally, section 6 holds the conclusions. The source code of the samples is held at compressed file " ParallelPIC_examples. zip ". The code for the supporting software that runs on the PC is stored into file " ParallelPIC_PCcode_V2. zip " and the source code (and the hex files) of the firmware is stored into the file " ParallelPIC_firmwareV2.
zip ". This parallel computer is of type Single Instruction Multiple Data (SIMD) which means that all MCUs execute the same program, but each MCU works with different data. (As a matter of fact, there are time instances where only one subset of the MCUs executes actual code while the other MCUs do nothing.
This is inherent in some parallel algorithms and will be shown in details in a subsequent section). The MCUs communicate with other MCUs to exchange data. Thus a network is developed between the MCUs. The topology of this network affects the design of the algorithms that are executed in the parallel machine. The parallel machine can be represented graphically by using circles for the MCUs and arcs for the interconnections between them.
(There may be one-way or two-way communication between two MCUs). The following figure shows two common topologies: An example of the use of the tree may be useful: Suppose that the problem is to find the maximum between 8 numbers. We use the tree structure shown in the above figure. The MCUs 1, 2, 3, 4 are called leaves . The MCU 7 is called root . The leaves get the input data. Each MCU compares the two (2) incoming data values, find the maximum and passes it to the upper MCU.
This means that -for example- MCU number 5 gets two values from MCUs 1 and 2 and passes the maximum to MCU 7. This read-compare-send algorithm is repeatedly executed. This way the root MCU (7) will hold the maximum of the eight (8) input numbers after three (3) executions of the read-compare-send algorithm: in the first execution the MCUs 1, 2, 3, 4 will send correct results to their upper MCUs, in the second execution MCUs 5, 6 will send correct results, and finally in the third execution MCU 7 will have the maximum Many algorithms have been developed for solving problems in this type of parallel machines covering many areas from elementary operations such as enumeration to complex operations such as Fourier Transforms, optimization and so on.
The interconnection network plays an important role in the efficiency of the algorithm. The most powerful network is the one where each MCU communicates with all the others. However, this is not a practical network and all the algorithms concentrate on simpler networks. A critical parameter is the number of connection for each MCU. The mesh topology requires that each MCU is connected with at most four (4) other MCUs. The binary tree requires three (3) connections per MCU. A very pow 🔗 External reference
Related Circuits
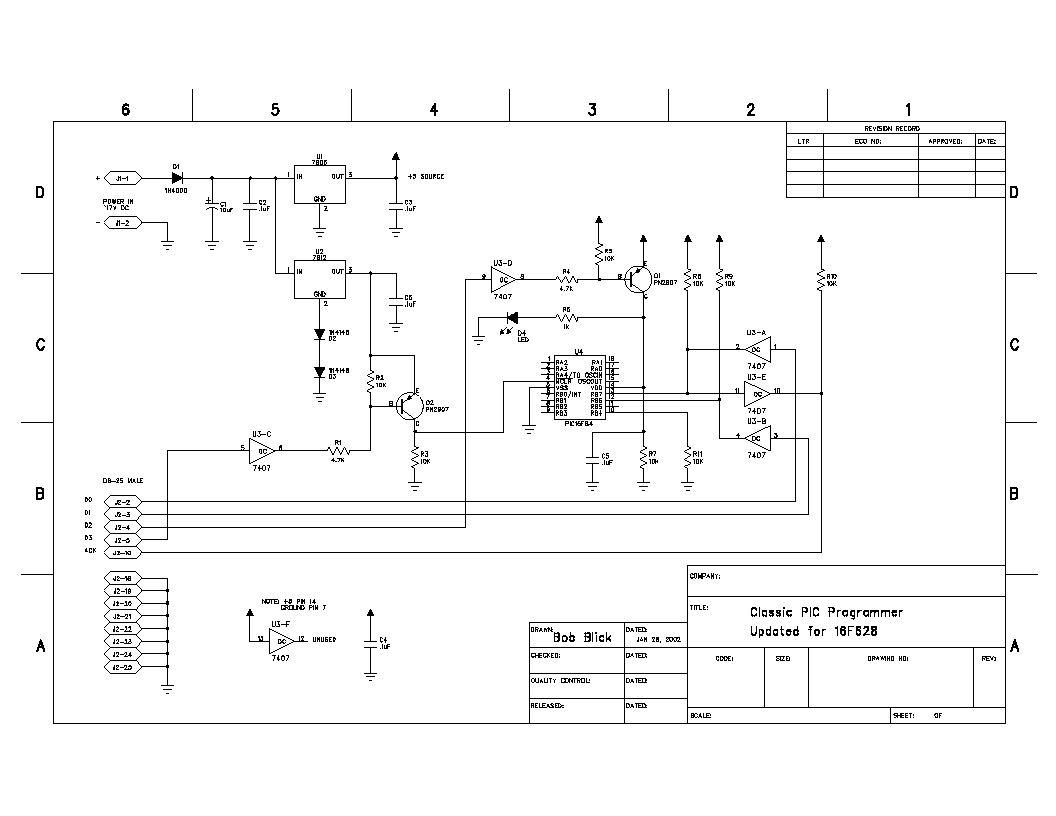
This is my own version of the classic PIC 16C84/16F84 programmer. The design is originally by David Tait. I’ve made a few changes, redrawn the schematic and done a board layout. All the files you will need are linked...

A small ultrasonic cleaning device currently operates with one 50W transducer. There are plans to construct another device using two 20W transducers, and the best configuration for wiring them—either in series or in parallel—is being considered. The circuit designs...
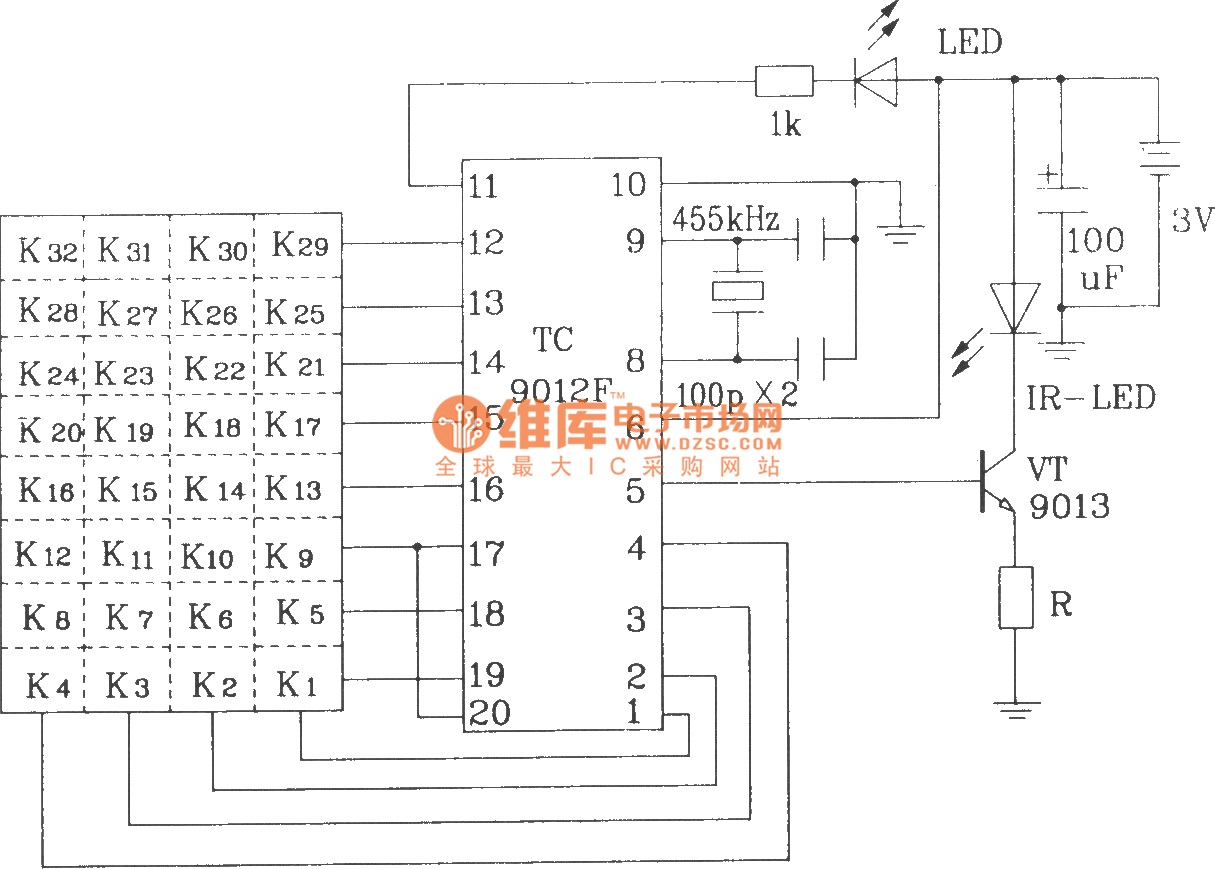
The TC9012 is a specialized off-screen remote control code transmitter. It incorporates an oscillator, divider timing generator, system code latch, data storage, key scan input, key scan output, and carrier control and output units. The internal 8-bit system code...
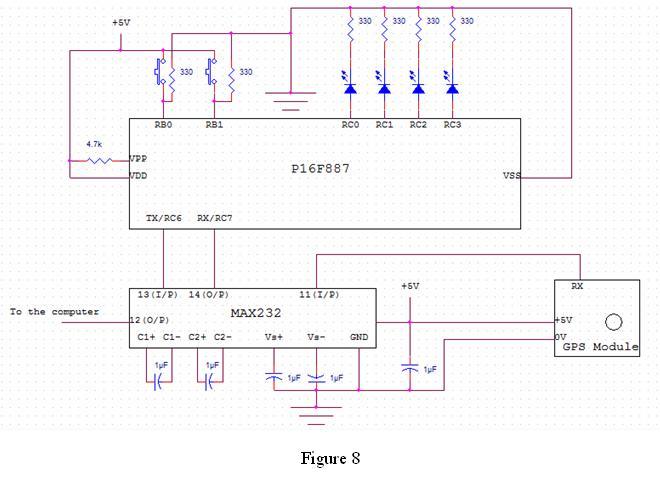
The anti-theft system includes two frequency sirens connected to the vehicle's immobilizer system. In the laboratory simulation model, the changes in operating modes, siren activation, and fuel supply cut-off are indicated by the illumination of LEDs and communicated to...
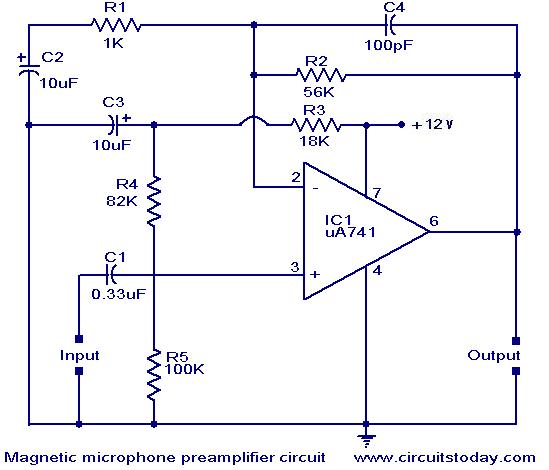
A preamplifier for magnetic pickups of record players is presented. The uA 741 is utilized as an AC-coupled non-inverting amplifier operating on a single supply. The amplifier gain is determined by the feedback components, where C2 manages the low-frequency...
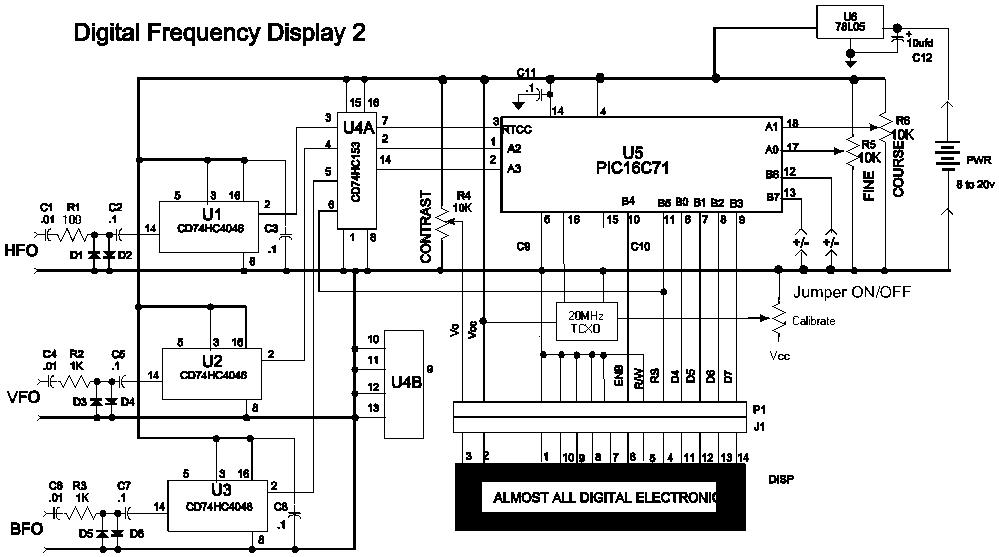
Power the frequency counter and adjust the coarse (top pot) and fine (bottom pot) controls to display zero frequency. Turn the pots counter-clockwise to achieve a zero reading. Occasionally, the counter may show only squares without digits. If this...
Warning: include(partials/cookie-banner.php): Failed to open stream: Permission denied in /var/www/html/nextgr/view-circuit.php on line 713
Warning: include(): Failed opening 'partials/cookie-banner.php' for inclusion (include_path='.:/usr/share/php') in /var/www/html/nextgr/view-circuit.php on line 713